Discord-Dialogues
A large-scale dataset of anonymized Discord conversations from late spring to early fall 2025 for training and evaluating conversational AI models in a ChatML-friendly format.
This dataset contains 7,303,464 exchanges spread out over 16,881,010 turns, with more than 139,922,950 words.
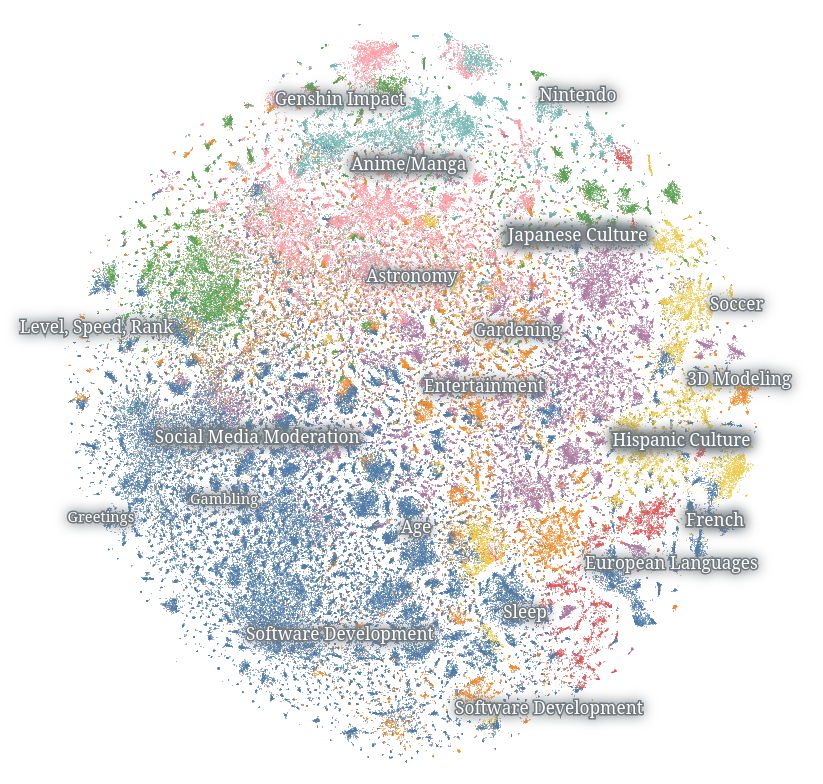 View on Nomic
Atlas
View on Nomic
Atlas
Features
- Mixed single and multi-turn exchanges
- Human-only dialogues (no bots)
- Filtered for ToS and harmful content
- Links, embeds, and commands removed
- Trading posts, code blocks, and LFG removed
- Two-author chains only
- Merged self-replies from the same author into a single message
- Cleaned and deduplicated for relevance
- Primarily English, with some other languages present
Use
- Fine-tuning conversational models
- Training relevance/reward models
- Dialogue generation research
Use case example: mookiezi/Discord-Micae-8B-Preview
Collection Policy
All data was collected adhering to Discord's Terms of Service.
Dataset Statistics
(Hermes-3-Llama-3.1-8B tokenizer)
| Metric | Value |
|---|---|
| Samples (count) | 7,303,464 |
| Total turns | 16,881,010 |
| Total assistant turns | 9,016,287 |
| Min length (tokens) | 10 |
| Max length (tokens) | 2,542 |
| Mean length (tokens) | 32.79 |
| Median length (tokens) | 28 |
| Std dev (tokens) | 16.56 |
| Skew | 6.04 |
| Kurtosis | 326.54 |
| Total tokens | 239,458,213 |
| Total characters | 1,242,238,794 |
| Total words | 139,922,950 |
| Avg chars per sample | 170.09 |
| Avg words per sample | 19.16 |
| Avg chars per word | 8.88 |
| Tokens per char | 0.19 |
Tokens
| 8–16 | 107,264 |
| 16–32 | 4,278,713 |
| 32–64 | 2,566,176 |
| 64–128 | 334,829 |
| 128–256 | 15,920 |
| 256–384 | 363 |
| 384–512 | 71 |
| 512–768 | 78 |
| 768–1024 | 30 |
| 1024–2048 | 17 |
| 2048–4096 | 3 |
Turns per Exchange
| 2 | 5,795,019 |
| 3 | 1,038,500 |
| 4 | 304,442 |
| 5 | 96,758 |
| 6 | 38,620 |
| 7 | 15,714 |
| 8 | 7,108 |
| 9 | 3,391 |
| 10 | 1,709 |
| 11 | 909 |
| 12 | 526 |
| 13 | 291 |
| 14 | 163 |
| 15 | 113 |
| 16 | 58 |
| 17 | 57 |
| 18 | 28 |
| 19 | 20 |
| 20 | 7 |
| 21 | 10 |
| 22 | 10 |
| 23 | 2 |
| 24 | 1 |
| 25 | 2 |
| 27 | 2 |
| 29 | 1 |
| 32 | 1 |
| 33 | 2 |